Configuring a subject source
Grouper uses subject sources to provide additional attributes about the entities it uses from sources of authority such as:
- HRS, SIS
- Active Directory
- LDAP
These attributes can include:
- Unique identifiers
- Names (legal, preferred, etc)
- Contact (email, phone, address, etc)
- Affiliations (emeritus, faculty, staff, student, etc)
- Entitlements
Before running Grouper you need to configure a subject source. This is done by editing the sources.xml file. The unedited version looks like this:
| Code Block |
|---|
<?xml version="1.0" encoding="utf-8"?>
<!--
Grouper's subject resolver configuration
$Id: sources.example.xml,v 1.8 2009-08-11 20:18:09 mchyzer Exp $
-->
<sources>
<!-- Group Subject Resolver -->
<!--
You can make virtual attributes (attributes with formatting or based on other attributes) like this:
init-param name is subjectVirtualAttribute_<index>_<name> where index is the order to be processed
if some depend on others (0 to 99). The value is the jexl expression language. You can use subjectUtils
methods (aliased with "subjectUtils", or you can register your own class (must have default constructor).
Here are examples:
<init-param>
<param-name>subjectVirtualAttribute_0_loginIdLfName</param-name>
<param-value>Hey ${subject.getAttributeValue('LOGINID')} and ${subject.getAttributeValue('LFNAME')}</param-value>
</init-param>
<init-param>
<param-name>subjectVirtualAttribute_1_loginIdLfNameLoginId</param-name>
<param-value>${subject.getAttributeValue('loginIdLfName')} Hey ${subject.getAttributeValue('LOGINID')} and ${subject.getAttributeValue('LFNAME')}</param-value>
</init-param>
<init-param>
<param-name>subjectVirtualAttributeVariable_JDBCSourceAdapterTest</param-name>
<param-value>edu.internet2.middleware.subject.provider.JDBCSourceAdapterTest</param-value>
</init-param>
<init-param>
<param-name>subjectVirtualAttribute_2_loginIdSquared</param-name>
<param-value>${JDBCSourceAdapterTest.appendToSelf(subject.getAttributeValue('LOGINID'))}</param-value>
</init-param>
The first virtual attribute is accessible via: subject.getAttributeValue("loginIdLfNameLoginId");
-->
<!--
NOTE: It is recommended that you **not** change the default
values for this source adapter.
-->
<source adapterClass="edu.internet2.middleware.grouper.GrouperSourceAdapter">
<id>g:gsa</id>
<name>Grouper: Group Source Adapter</name>
<type>group</type>
</source>
<!-- Group Subject Resolver -->
<source adapterClass="edu.internet2.middleware.grouper.subj.GrouperJdbcSourceAdapter">
<id>jdbc</id>
<name>Example JDBC Source Adapter</name>
<type>person</type>
<!-- edu.internet2.middleware.subject.provider.C3p0JdbcConnectionProvider (default)
edu.internet2.middleware.subject.provider.DbcpJdbcConnectionProvider (legacy)
edu.internet2.middleware.grouper.subj.GrouperJdbcConnectionProvider
(same settings as grouper.hibernate.properties, the driver, url, pass, maxActive, maxIdle, maxWait are forbidden -->
<init-param>
<param-name>jdbcConnectionProvider</param-name>
<param-value>edu.internet2.middleware.grouper.subj.GrouperJdbcConnectionProvider </param-value>
</init-param>
<!-- note: again, if you use GrouperJdbcConnectionProvider, then you should not fill out maxActive, maxIdle,
maxWait, dbDriver, dbUrl, dbUser, dbPwd, since it will use the grouper.hibernate.properties db settings -->
<!-- init-param>
<param-name>maxActive</param-name>
<param-value>16</param-value>
</init-param>
<init-param>
<param-name>maxIdle</param-name>
<param-value>16</param-value>
</init-param>
<init-param>
<param-name>maxWait</param-name>
<param-value>-1</param-value>
</init-param -->
<!--
e.g. mysql: com.mysql.jdbc.Driver
e.g. p6spy (log sql): com.p6spy.engine.spy.P6SpyDriver
for p6spy, put the underlying driver in spy.properties
e.g. oracle: oracle.jdbc.driver.OracleDriver
e.g. hsqldb: org.hsqldb.jdbcDriver
e.g. postgres: org.postgresql.Driver -->
<!-- init-param>
<param-name>dbDriver</param-name>
<param-value>org.hsqldb.jdbcDriver</param-value>
</init-param -->
<!--
e.g. mysql: jdbc:mysql://localhost:3306/grouper
e.g. p6spy (log sql): [use the URL that your DB requires]
e.g. oracle: jdbc:oracle:thin:@server.school.edu:1521:sid
e.g. hsqldb (a): jdbc:hsqldb:dist/run/grouper;create=true
e.g. hsqldb (b): jdbc:hsqldb:hsql://localhost:9001
e.g. postgres: jdbc:postgresql:grouper -->
<!-- init-param>
<param-name>dbUrl</param-name>
<param-value>jdbc:hsqldb:C:/projects/GrouperI2MI_1-2/grouper/dist/run/grouper</param-value>
</init-param>
<init-param>
<param-name>dbUser</param-name>
<param-value>sa</param-value>
</init-param>
<init-param>
<param-name>dbPwd</param-name>
<param-value></param-value>
</init-param -->
<init-param>
<param-name>SubjectID_AttributeType</param-name>
<param-value>id</param-value>
</init-param>
<init-param>
<param-name>Name_AttributeType</param-name>
<param-value>name</param-value>
</init-param>
<init-param>
<param-name>Description_AttributeType</param-name>
<param-value>description</param-value>
</init-param>
<search>
<searchType>searchSubject</searchType>
<param>
<param-name>sql</param-name>
<param-value>
select
s.subjectid as id, s.name as name,
(select sa2.value from subjectattribute sa2 where name='name' and sa2.SUBJECTID = s.subjectid) as lfname,
(select sa3.value from subjectattribute sa3 where name='loginid' and sa3.SUBJECTID = s.subjectid) as loginid,
(select sa4.value from subjectattribute sa4 where name='description' and sa4.SUBJECTID = s.subjectid) as description
from
subject s
where
s.subjectid = ?
</param-value>
</param>
</search>
<search>
<searchType>searchSubjectByIdentifier</searchType>
<param>
<param-name>sql</param-name>
<param-value>
select
s.subjectid as id, s.name as name,
(select sa2.value from subjectattribute sa2 where name='name' and sa2.SUBJECTID = s.subjectid) as lfname,
(select sa3.value from subjectattribute sa3 where name='loginid' and sa3.SUBJECTID = s.subjectid) as loginid,
(select sa4.value from subjectattribute sa4 where name='description' and sa4.SUBJECTID = s.subjectid) as description
from
subject s, subjectattribute a
where
a.value = ? and a.name='loginid' and s.subjectid = a.subjectid
</param-value>
</param>
</search>
<search>
<searchType>search</searchType>
<param>
<param-name>sql</param-name>
<!-- for postgres, use this query since no concat() exists:
select
subject.subjectid as id, subject.name as name,
lfnamet.lfname as lfname, loginidt.loginid as loginid,
desct.description as description
from
subject
left join (select subjectid, value as lfname from subjectattribute
where name='name') lfnamet
on subject.subjectid=lfnamet.subjectid
left join (select subjectid, value as loginid from subjectattribute
where name='loginid') loginidt
on subject.subjectid=loginidt.subjectid
left join (select subjectid, value as description from subjectattribute
where name='description') desct
on subject.subjectid=desct.subjectid
where
(lower(name) like '%' || ? || '%')
or (lower(lfnamet.lfname) like '%' || ? || '%')
or (lower(loginidt.loginid) like '%' || ? || '%')
or (lower(desct.description) like '%' || ? || '%')
-->
<param-value>
select
s.subjectid as id, s.name as name,
(select sa2.value from subjectattribute sa2 where name='name' and sa2.SUBJECTID = s.subjectid) as lfname,
(select sa3.value from subjectattribute sa3 where name='loginid' and sa3.SUBJECTID = s.subjectid) as loginid,
(select sa4.value from subjectattribute sa4 where name='description' and sa4.SUBJECTID = s.subjectid) as description
from
subject s
where
s.subjectid in (
select subjectid from subject where lower(name) like concat('%',concat(?,'%')) union
select subjectid from subjectattribute where searchvalue like concat('%',concat(?,'%'))
)
</param-value>
</param>
</search>
</source>
<!--
<!- - This is an alternate jdbc source which allows for more complex searches, assumes
all data is in one table or view, and that all attributes are single valued. There are
not queries to configure in sources.xml - - >
<source adapterClass="edu.internet2.middleware.grouper.subj.GrouperJdbcSourceAdapter2">
<id>sourceId</id>
<name>Source name</name>
<type>person</type>
<init-param>
<param-name>jdbcConnectionProvider</param-name>
<param-value>edu.internet2.middleware.grouper.subj.GrouperJdbcConnectionProvider</param-value>
</init-param>
<init-param>
<param-name>dbTableOrView</param-name>
<param-value>person_source_v</param-value>
</init-param>
<init-param>
<param-name>subjectIdCol</param-name>
<param-value>some_id</param-value>
</init-param>
<init-param>
<param-name>nameCol</param-name>
<param-value>name</param-value>
</init-param>
<init-param>
<param-name>descriptionCol</param-name>
<param-value>description</param-value>
</init-param>
<init-param>
<!- - search col where general searches take place, lower case - - >
<param-name>lowerSearchCol</param-name>
<param-value>description_lower</param-value>
</init-param>
<init-param>
<!- - optional col if you want the search results sorted in the API (note, UI might override) - - >
<param-name>defaultSortCol</param-name>
<param-value>description</param-value>
</init-param>
<init-param>
<!- - col which identifies the row, perhaps not subjectId, add multiple by incrementing the 0 index - - >
<param-name>subjectIdentifierCol0</param-name>
<param-value>pennname</param-value>
</init-param>
<init-param>
<!- - col which identifies the row, perhaps not subjectId, add multiple by incrementing the 0 index - - >
<param-name>subjectIdentifierCol1</param-name>
<param-value>penn_id</param-value>
</init-param>
<!- - now you can count up from 0 to N of attributes for various cols.
The name is how to reference in subject.getAttribute() - - >
<init-param>
<param-name>subjectAttributeCol0</param-name>
<param-value>pennname</param-value>
</init-param>
<init-param>
<param-name>subjectAttributeName0</param-name>
<param-value>PENNNAME</param-value>
</init-param>
</source>
-->
<!--
<source adapterClass="edu.internet2.middleware.grouper.subj.GrouperJndiSourceAdapter">
<id>example</id>
<name>Example Edu</name>
<type>person</type>
<init-param>
<param-name>INITIAL_CONTEXT_FACTORY</param-name>
<param-value>com.sun.jndi.ldap.LdapCtxFactory</param-value>
</init-param>
<init-param>
<param-name>PROVIDER_URL</param-name>
<param-value>ldap://localhost:389</param-value>
</init-param>
<init-param>
<param-name>SECURITY_AUTHENTICATION</param-name>
<param-value>simple</param-value>
</init-param>
<init-param>
<param-name>SECURITY_PRINCIPAL</param-name>
<param-value>cn=Manager,dc=example,dc=edu</param-value>
</init-param>
<init-param>
<param-name>SECURITY_CREDENTIALS</param-name>
<param-value>secret</param-value>
</init-param>
<init-param>
<param-name>SubjectID_AttributeType</param-name>
<param-value>exampleEduRegID</param-value>
</init-param>
<init-param>
<param-name>Name_AttributeType</param-name>
<param-value>cn</param-value>
</init-param>
<init-param>
<param-name>Description_AttributeType</param-name>
<param-value>description</param-value>
</init-param>
/// Scope Values can be: OBJECT_SCOPE, ONELEVEL_SCOPE, SUBTREE_SCOPE
/// For filter use
<search>
<searchType>searchSubject</searchType>
<param>
<param-name>filter</param-name>
<param-value>
(& (exampleEduRegId=%TERM%) (objectclass=exampleEduPerson))
</param-value>
</param>
<param>
<param-name>scope</param-name>
<param-value>
SUBTREE_SCOPE
</param-value>
</param>
<param>
<param-name>base</param-name>
<param-value>
ou=people,dc=example,dc=edu
</param-value>
</param>
</search>
<search>
<searchType>searchSubjectByIdentifier</searchType>
<param>
<param-name>filter</param-name>
<param-value>
(& (uid=%TERM%) (objectclass=exampleEduPerson))
</param-value>
</param>
<param>
<param-name>scope</param-name>
<param-value>
SUBTREE_SCOPE
</param-value>
</param>
<param>
<param-name>base</param-name>
<param-value>
ou=people,dc=example,dc=edu
</param-value>
</param>
</search>
<search>
<searchType>search</searchType>
<param>
<param-name>filter</param-name>
<param-value>
(& (|(uid=%TERM%)(cn=*%TERM%*)(exampleEduRegId=%TERM%))(objectclass=exampleEduPerson))
</param-value>
</param>
<param>
<param-name>scope</param-name>
<param-value>
SUBTREE_SCOPE
</param-value>
</param>
<param>
<param-name>base</param-name>
<param-value>
ou=people,dc=example,dc=edu
</param-value>
</param>
</search>
///Attributes you would like to display when doing a search
<attribute>sn</attribute>
<attribute>department</attribute>
</source>
-->
</sources>
|
The file contains 4 sources, 3 of which are subject sources, of which 2 are commented out.
- The first is an edu.internet2.middleware.grouper.GrouperSourceAdapter which tells Grouper where to find its groups. This will normally be left as it is
- The second is an edu.internet2.middleware.grouper.subj.GrouperJdbcSourceAdapter which has a partial configuration for obtaining subject data from a database. This adaptor contains queries for retrieving the data which can be written to suit the underlying database schema. It extracts a standard set of subject attributes
- The third is an edu.internet2.middleware.grouper.subj.GrouperJdbcSourceAdapter2 which also obtains subject data from a database, but requires that the data is available in a single table or view. It enables you to extract additional attributes from the database for use in Grouper
- The fourth is an edu.internet2.middleware.grouper.subj.GrouperJndiSourceAdapter which is used to source subject data from a JNDI source, such as an LDAP directory
Configuring a JDBC subject source adaptor 1 - a GrouperJdbcSourceAdapter
If your subject data is present in a database you will be using one of the two types of Jdbc Source Adaptors. Your database needs to contain the following in order to be suitable for consumption as a subject source:
Each subject (normally a person) must be present in the database with t he following data
- a single unique, persistent identifier which will always refer to the same person.
- a name
- a description
You will need to provide SQL queries to search your database for user supplied strings and return the identifier, name and description. Table joins, concatenation, functions and anything else which is valid in an SQL query that your database supports can be used in these queries. Three queries are defined for the subject source, each of which should return exactly one row per subject:
- subjectSearch - where the data is retrieved using a query with the identifier only. This is used frequently by Grouper and you should ensure that it is fast. You may wish to optimise your database with indexing to increase performance
- searchSubjectByIdentifier - needs to be configured to comply with the subject API, but what is it actually used for???
- search - the query used by Grouper whenever a general search is performed. For example, a query in the UI to find people to add to a group will use this query. You should make sure that data that people would expect to be searched (such as name) are queried. You will also need to consider case-sensitivity and wildcard searching
The queries must make the data retrieved available to grouper using three column names. These column names must be the same across all three queries. The names are configurable
The identifier may be a primary key column in the database. You may also wish to consider using data such as usernames or email addresses, but be sure that these will never change for a person. Bear in mind that your choice may be influenced by the destination of your grouper groups data. You may be making your overall system simpler and easier to maintain if you choose an identifier which is meaningful to systems which are going to consume your groups data.
The connection to the database can be made using one of three ways:
- If your subject data is stored in the same database as the grouper tables you can use the edu.internet2.middleware.grouper.subj.GrouperJdbcConnectionProvider provider. If you use this then all the connection information is taken from grouper.hibernate.properties and you should not define it in sources.xml
- If your subject data is stored in a different database then you should use the C3PO connection pool provider. This is a java library that provides reliable, high performance database connections
- You may choose to use an Apache Database Connection Pool (DBCP) provider. This is deprecated, so you should only use it if C3PO is not a viable option
Example configuration of a subject data source against a C3p0JdbcConnectionProvider connection to a postgres database where subject data is available from a single, flat table:
| Code Block |
|---|
<source adapterClass="edu.internet2.middleware.grouper.subj.GrouperJdbcSourceAdapter">
<id>postgresSubjectSource</id>
<name>Subject JDBC Source Adapter</name>
<type>person</type>
<init-param>
<param-name>jdbcConnectionProvider</param-name>
<param-value>edu.internet2.middleware.subject.provider.C3p0JdbcConnectionProvider</param-value>
</init-param>
<init-param>
<param-name>maxActive</param-name>
<param-value>16</param-value>
</init-param>
<init-param>
<param-name>maxIdle</param-name>
<param-value>16</param-value>
</init-param>
<init-param>
<param-name>maxWait</param-name>
<param-value>-1</param-value>
</init-param>
<init-param>
<param-name>dbDriver</param-name>
<param-value>org.postgresql.Driver</param-value>
</init-param>
<init-param>
<param-name>dbUrl</param-name>
<param-value>jdbc:postgresql://localhost/subjectdata</param-value>
</init-param>
<init-param>
<param-name>dbUser</param-name>
<param-value>grouper</param-value>
</init-param>
<init-param>
<param-name>dbPwd</param-name>
<param-value>grouper</param-value>
</init-param>
<init-param>
<param-name>SubjectID_AttributeType</param-name>
<param-value>cn</param-value>
</init-param>
<init-param>
<param-name>Name_AttributeType</param-name>
<param-value>fullname</param-value>
</init-param>
<init-param>
<param-name>Description_AttributeType</param-name>
<param-value>descriptionconcat</param-value>
</init-param>
<search>
<searchType>searchSubject</searchType>
<param>
<param-name>sql</param-name>
<param-value>
select cn, sn || ', ' || givenName AS fullname, cardiffidmandept AS descriptionconcat FROM objectdata.rre_objects_dn WHERE cn = ?
</param-value>
</param>
</search>
<search>
<searchType>searchSubjectByIdentifier</searchType>
<param>
<param-name>sql</param-name>
<param-value>
select cn, sn || ', ' || givenName AS fullname, cardiffidmandept AS descriptionconcat FROM objectdata.rre_objects_dn WHERE cardiffidmanmailname = ?
</param-value>
</param>
</search>
<search>
<searchType>search</searchType>
<param>
<param-name>sql</param-name>
<param-value>
select cn, sn || ', ' || givenName AS fullname, cardiffidmandept AS descriptionconcat FROM objectdata.rre_objects_dn WHERE parent_object_id IS NOT NULL AND (cn ILIKE ? OR sn ILIKE '%' || ? || '%' OR cardiffidmanmailname ILIKE '%' || ? || '%')
</param-value>
</param>
</search>
</source>
|
Troubleshooting advice: you will probably want to test your queries outside of Grouper as this will make it easier to debug them. You can use you favourite SQL client for this. Parameters are passed into queries by substituting the ? character(s) in queries with the real data, so you can switch between using real data in you tests and the substitution character in the grouper configuration.
Configuring a JDBC subject source adaptor 2 - a GrouperJdbcSourceAdapter2
In the previous example we used a GrouperJdbcSourceAdapter. This used configured queries to return exactly three data columns for each subject. The GrouperJdbcSourceAdapter2 enables us to :
- Extract additional data from the database, but. Queries are not configured as they are built from the configuration of field mappings
- Conduct AND searches where you are searching using more than one word. For example, with the standard GrouperJdbcSourceAdapter a search for "john smith" would search for the string in it entirety. You may wrap it in wildcards so than "john smithson" could be returned, but "john j smith" would not. GrouperJdbcSourceAdapter2 splits the search into 2 stages, first searching for "john" and then searching for "smith", therefore "john s smith" would be returned
Queries are restricted to a single table or view, so queries are not configured as they are built from the configuration parameters. This means most likely means that you will not be able to use GrouperJdbcSourceAdapter2 without some ability to modify the schema of the database you are querying, unless you are lucky enough to find an existing table or view which is appropriately structured.
The adapter requires a table or view with at least the following fields (though not necessarily with these names, as they can be configured):
- subjectIdCol - a persistent unique identifier for each person
- nameCol - the name of the person
- descriptionCol - the description of the person
- lowerSearchCol - a field containing data in lower case that will be searched. This may be a concatenation of name and description, or could include different or additional data. You will need to maintain this field in the database and could consider using a trigger to do so
An additional defaultSortCol parameter can be specified for sorting. This can be configured as one of the fields above, or an additional one contained in the table or view.
Each person must be represented by exactly one row, and each of these fields must return a single value (array data types are not supported).
Additional identifier columns can be specified using field definitions:
- subjectIdentifierCol0 - a subject identifier in additional to the subjectIdCol, multiple can be added by incrementing the number on the end (subjectIdentifierCol1, subjectIdentifierCol2 etc)
Need to follow up where these attributes are populated in the subject, and what they can be used for.
Additional non-identifier fields to return can also be specified with pairs of parameters:
- subjectAttributeCol0 - the name of the field containing the data in the database, subjectAttributeName0 - the name of the attribute in Grouper into which the data will be loaded. This attribute will be added automatically.
These identifiers are populated into the attributes on the subject, and are made available through various methods, such as getAttributes(), getAttributeValue().
Configuring a JNDI subject source adaptor
A Java Naming and Directory Interface (JNDI) adaptor can be used to connect to various data sources, including DNS, NIS, CORBA naming services and directory services. It is an interface specification and so vendors can expose data through JNDI if they choose. The most common use of JNDI in the Grouper environment is to connect to an LDAP directory for subject data, so we will use this as an example.
The example file contains a configuration which is suited to a directory such as OpenLDAP. A working configuration for Novell eDirectory might look like:
| Code Block |
|---|
<source adapterClass="edu.internet2.middleware.grouper.subj.GrouperJndiSourceAdapter">
<id>example</id>
<name>Example Edu</name>
<type>person</type>
<init-param>
<param-name>INITIAL_CONTEXT_FACTORY</param-name>
<param-value>com.sun.jndi.ldap.LdapCtxFactory</param-value>
</init-param>
<init-param>
<param-name>PROVIDER_URL</param-name>
<param-value>ldap://idman.cf.ac.uk:389</param-value>
</init-param>
<init-param>
<param-name>SECURITY_AUTHENTICATION</param-name>
<param-value>simple</param-value>
</init-param>
<init-param>
<param-name>SECURITY_PRINCIPAL</param-name>
<param-value>cn=idman,o=users</param-value>
</init-param>
<init-param>
<param-name>SECURITY_CREDENTIALS</param-name>
<param-value>password</param-value>
</init-param>
<init-param>
<param-name>SubjectID_AttributeType</param-name>
<param-value>CardiffIDManIdentityNo</param-value>
</init-param>
<init-param>
<param-name>Name_AttributeType</param-name>
<param-value>fullname</param-value>
</init-param>
<init-param>
<param-name>Description_AttributeType</param-name>
<param-value>CardiffIDManPreferredDescriptor</param-value>
</init-param>
/// Scope Values can be: OBJECT_SCOPE, ONELEVEL_SCOPE, SUBTREE_SCOPE
/// For filter use
<search>
<searchType>searchSubject</searchType>
<param>
<param-name>filter</param-name>
<param-value>
(& (fullName=%TERM%) (objectclass=inetOrgPerson))
</param-value>
</param>
<param>
<param-name>scope</param-name>
<param-value>
SUBTREE_SCOPE
</param-value>
</param>
<param>
<param-name>base</param-name>
<param-value>
o=people
</param-value>
</param>
</search>
<search>
<searchType>searchSubjectByIdentifier</searchType>
<param>
<param-name>filter</param-name>
<param-value>
(& (CardiffIDManIdentityNo=%TERM%) (objectclass=inetOrgPerson))
</param-value>
</param>
<param>
<param-name>scope</param-name>
<param-value>
SUBTREE_SCOPE
</param-value>
</param>
<param>
<param-name>base</param-name>
<param-value>
o=people
</param-value>
</param>
</search>
<search>
<searchType>search</searchType>
<param>
<param-name>filter</param-name>
<param-value>
(& (|(cn=*%TERM%*)(fullName=*%TERM%*))(objectclass=exampleEduPerson))
</param-value>
</param>
<param>
<param-name>scope</param-name>
<param-value>
SUBTREE_SCOPE
</param-value>
</param>
<param>
<param-name>base</param-name>
<param-value>
o=people
</param-value>
</param>
</search>
///Attributes you would like to display when doing a search
<attribute>sn</attribute>
<attribute>givenName</attribute>
<attribute>CardiffIDManDept</attribute>
</source>
|
INITIAL_CONTEXT_FACTORY | The class name used for the JNDI lookup. For LDAP this will be com.sun.jndi.ldap.LdapCtxFactory |
PROVIDER_URL | The URL to use to connect to the ldap server. For non-ssl connections this will be in the form ldap://<server name or IP>:<port> the standard port for LDAP is 389. For an SSL connection this will be in the form ldaps://<server name or IP>:<port> the standard port for secure LDAP is 636. LDAP also supports TLS over the standard port |
SECURITY_AUTHENTICATION | The type of authentication to use. "Simple "uses a username and password, but may not be supported by your LDAP directory. Valid alternatives include "None" and a valid SASL authentication mechanism |
SECURITY_PRINCIPAL | The distinguished name (DN) of the user used to bind to the directory before searching. Must have rights to read the data |
SECURITY_CREDENTIALS | If using Simple authentication, this will contain the password used to bind |
SubjectID_AttributeType | The attribute name to which contains a unique, persistent identifier for a person. You cannot assume that an LDAP directory will enforce with uniqueness or persistence since move operations (which changes the DN of an object), and rename operations (which changes the naming attributes of an object) are standard LDAP operations. Unless you are sure these operations are never going to be used, you will need to use an externally specified identifier which is maintained in you directory. |
Name_AttributeType | The LDAP attribute containing the name of the user |
Description_Attribute | The LDAP attribute containing the description of the user |
searchSubject | An LDAP search to use for a subject search |
base | The base specifies from where in the LDAP tree the search should start |
searchSubjectByIdentifier | An LDAP search to use to search for a subject by identifier |
search | A general search to use |
attribute | One or more attributes which you would like to display when doing a search |
in Home → Miscellaneous → Subject sources.
To add a subject source:
- Go to Actions → Add subject source
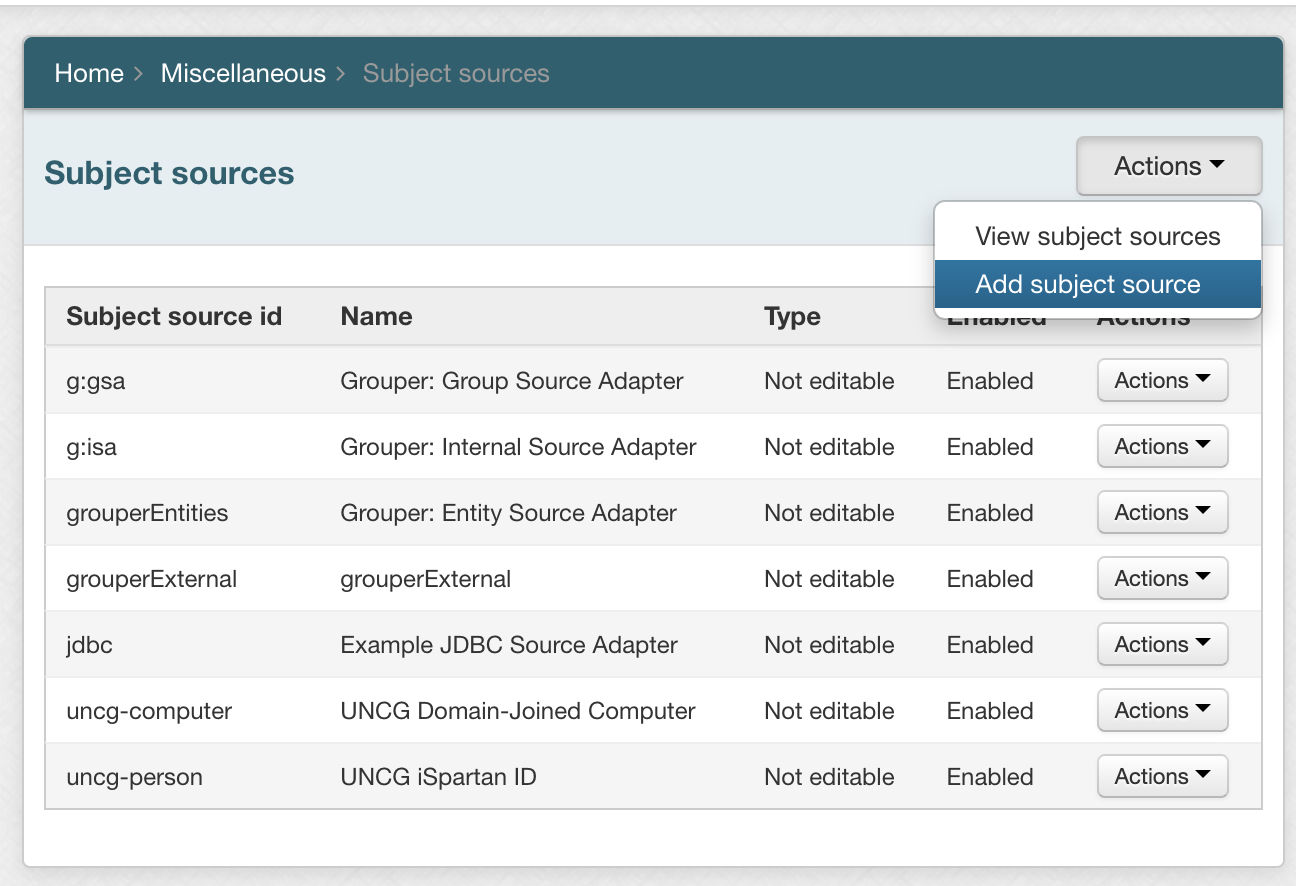
- Add:
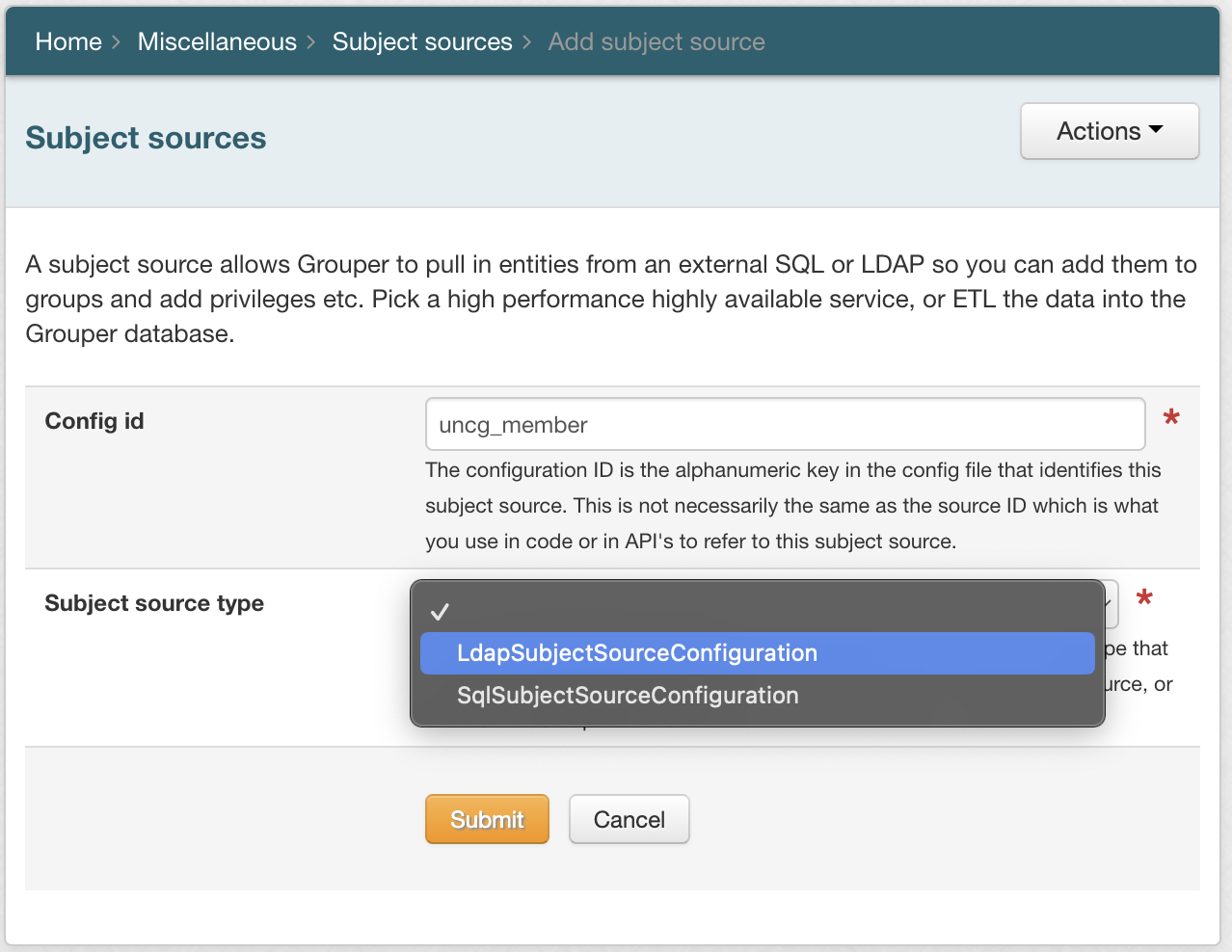
Config ID - the alphanumeric key in the config file that identifies this subject source. This is not necessarily the same as the source ID which is what you use in code or in API's to refer to this subject source
Subject source type (LDAPSubjectSourceConfiguration or SqlSubjectSourceConfiguration) - Currently Grouper supports these source types. If there is not a source type that you need you need to ETL the data into a database, or build a subject source, or contact the Grouper dev team
Click Submit. The page will update with new sections based on your Subject source type.
Configure General settings by adding:
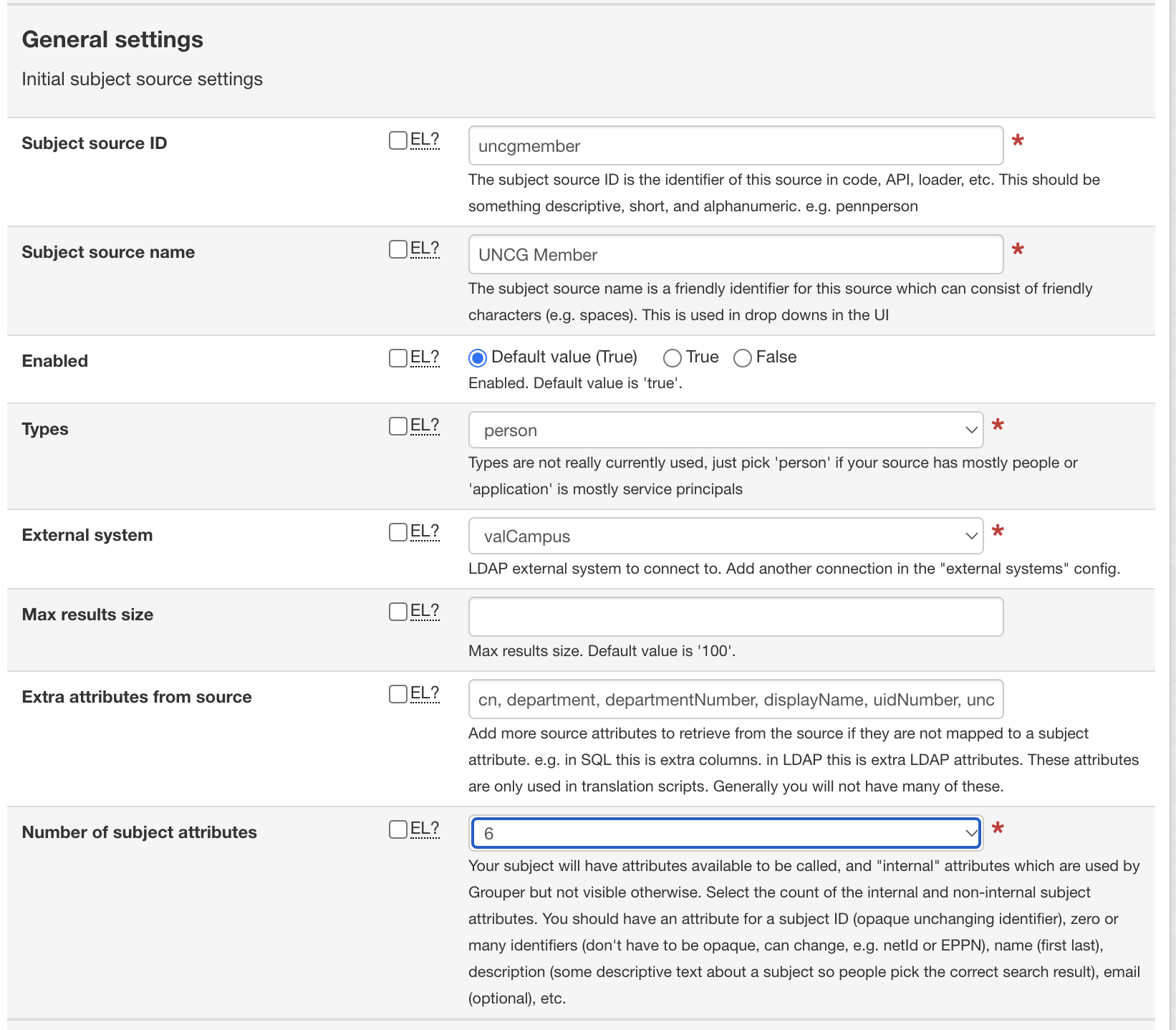
For each subject attribute, configure:
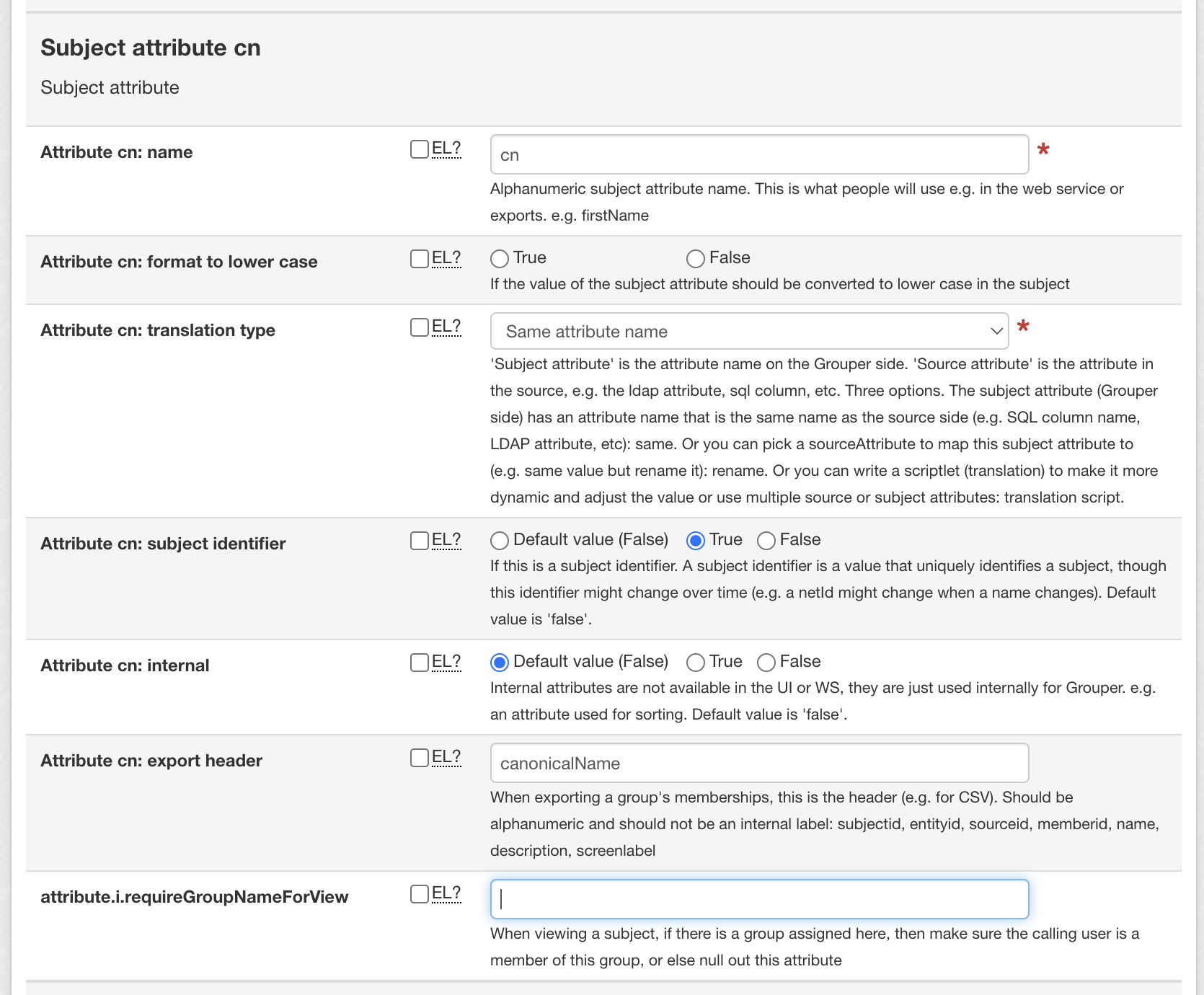
- For translation scripts, We may need variables from source, and variables for other subject attributes. suggestion is ${source_attribute__first_name} - gets an attribute from the source query or filter. in this case 'first_name' column ${subject_attribute__description} - references a built in subject field, in this case the description field ${subject_attribute__emailaddress} - references a previously configured subject attribute. in this case "emailAddress". The key is lower case.
- Description example: ${source_attribute__sn + ', ' + source_attribute__givenname + ' (' + subject_attribute__cn + ') (ADM)'}
- For translation scripts, We may need variables from source, and variables for other subject attributes. suggestion is ${source_attribute__first_name} - gets an attribute from the source query or filter. in this case 'first_name' column ${subject_attribute__description} - references a built in subject field, in this case the description field ${subject_attribute__emailaddress} - references a previously configured subject attribute. in this case "emailAddress". The key is lower case.
- Map subject fields by selecting the desired attributes for:
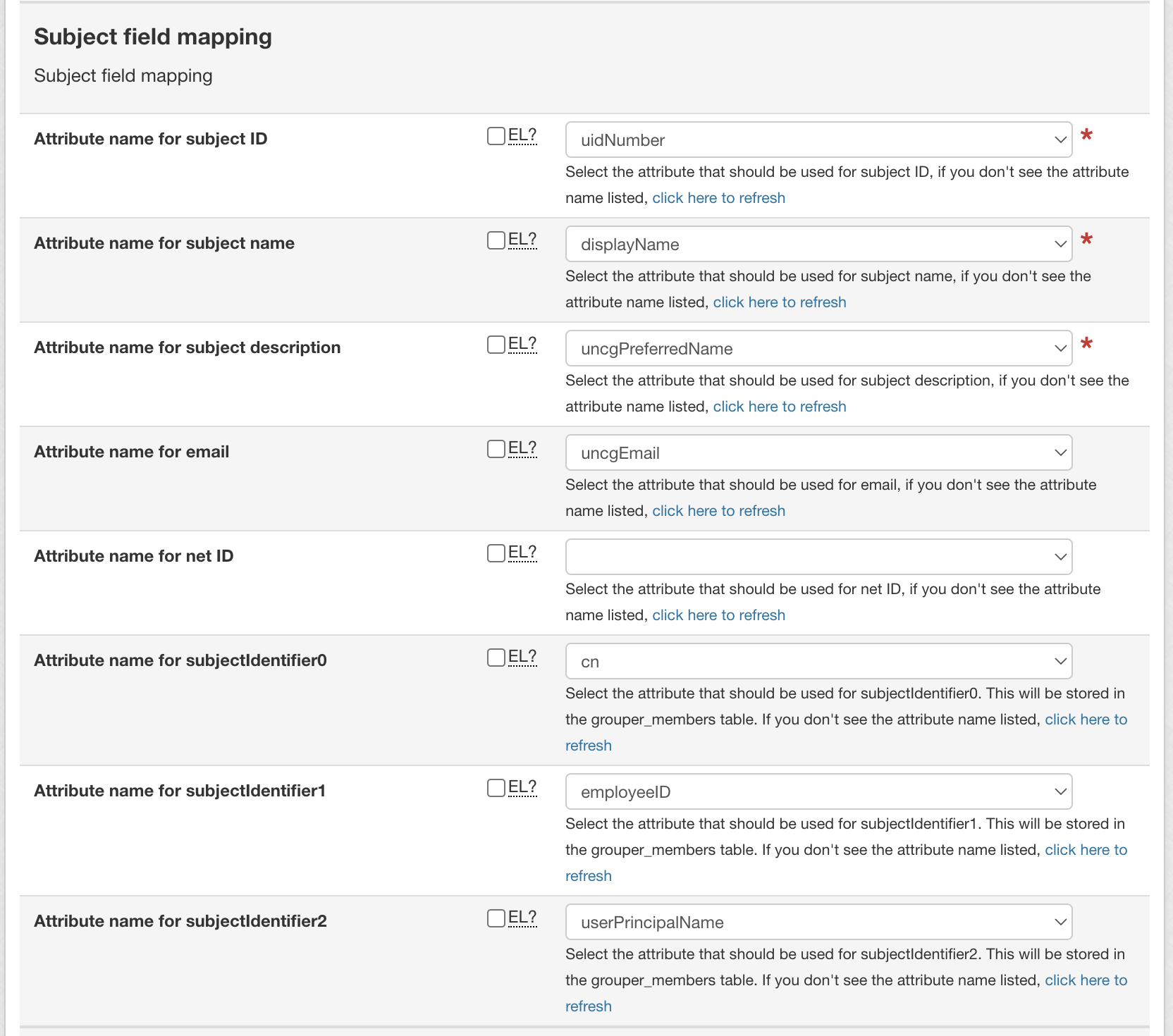
- Subject ID
- Name
- Description
- Net ID
- subjectIdentifier0-2
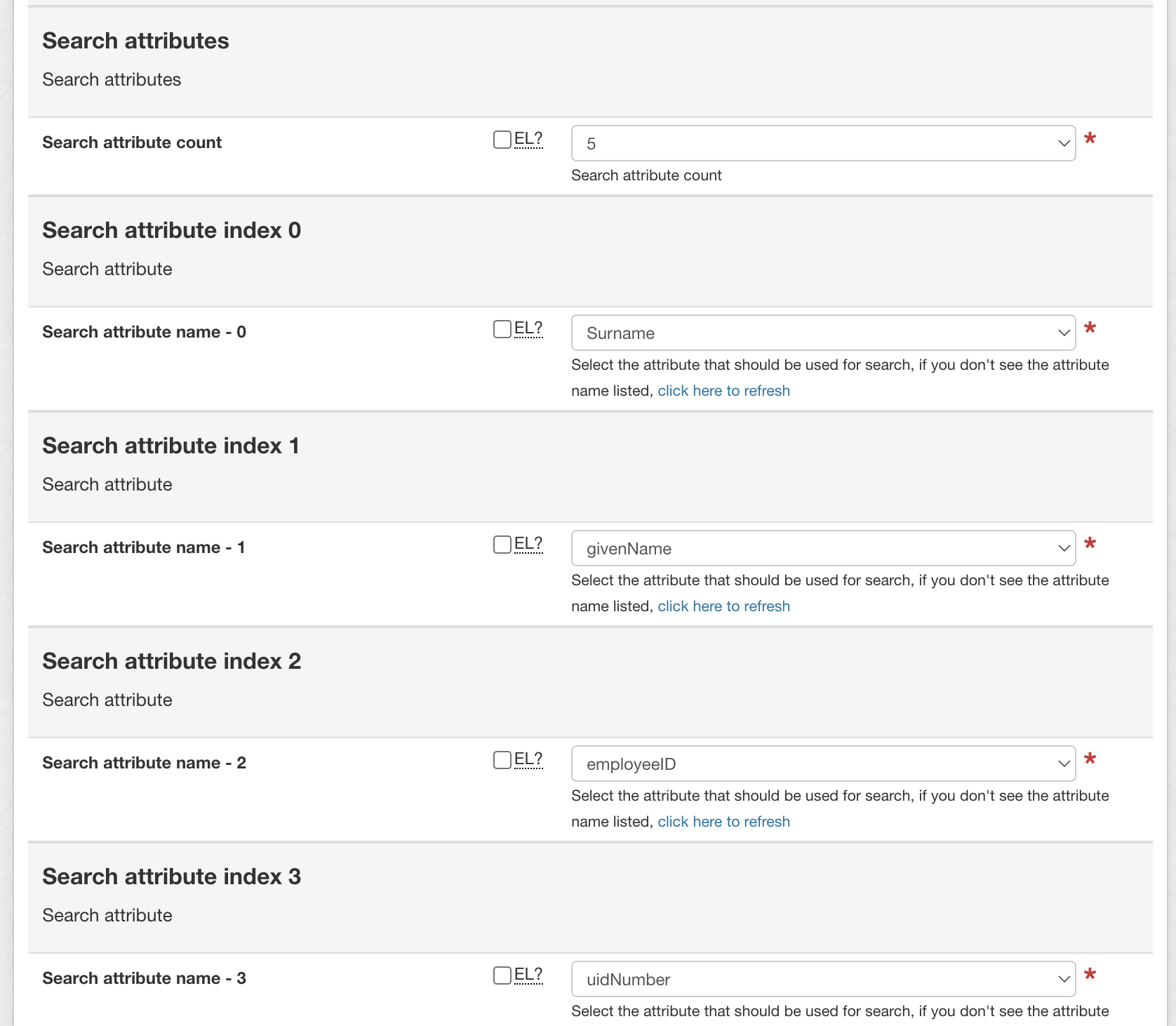
- Specify the number of attributes subjects can be searched by [1-5], then select the fields in the resulting drop-downs
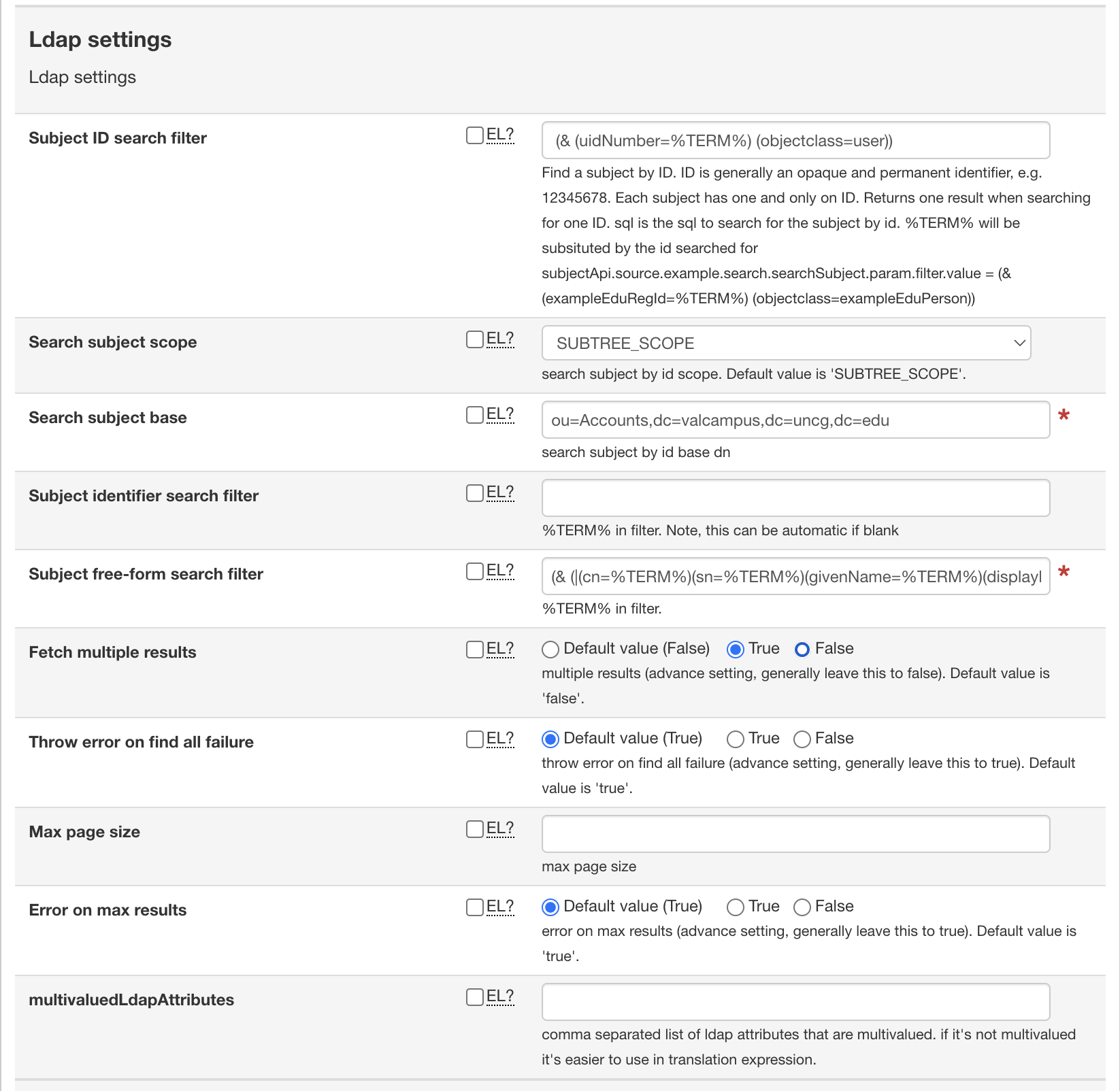
- Configure your LDAP Settings
- Configure the Configuration Check and Subject Source Diagnostics. Optional, but useful in troubleshooting and initial configuration (TODO: Steps and Screenshots)
- Click Submit to save your configuration
...
- .