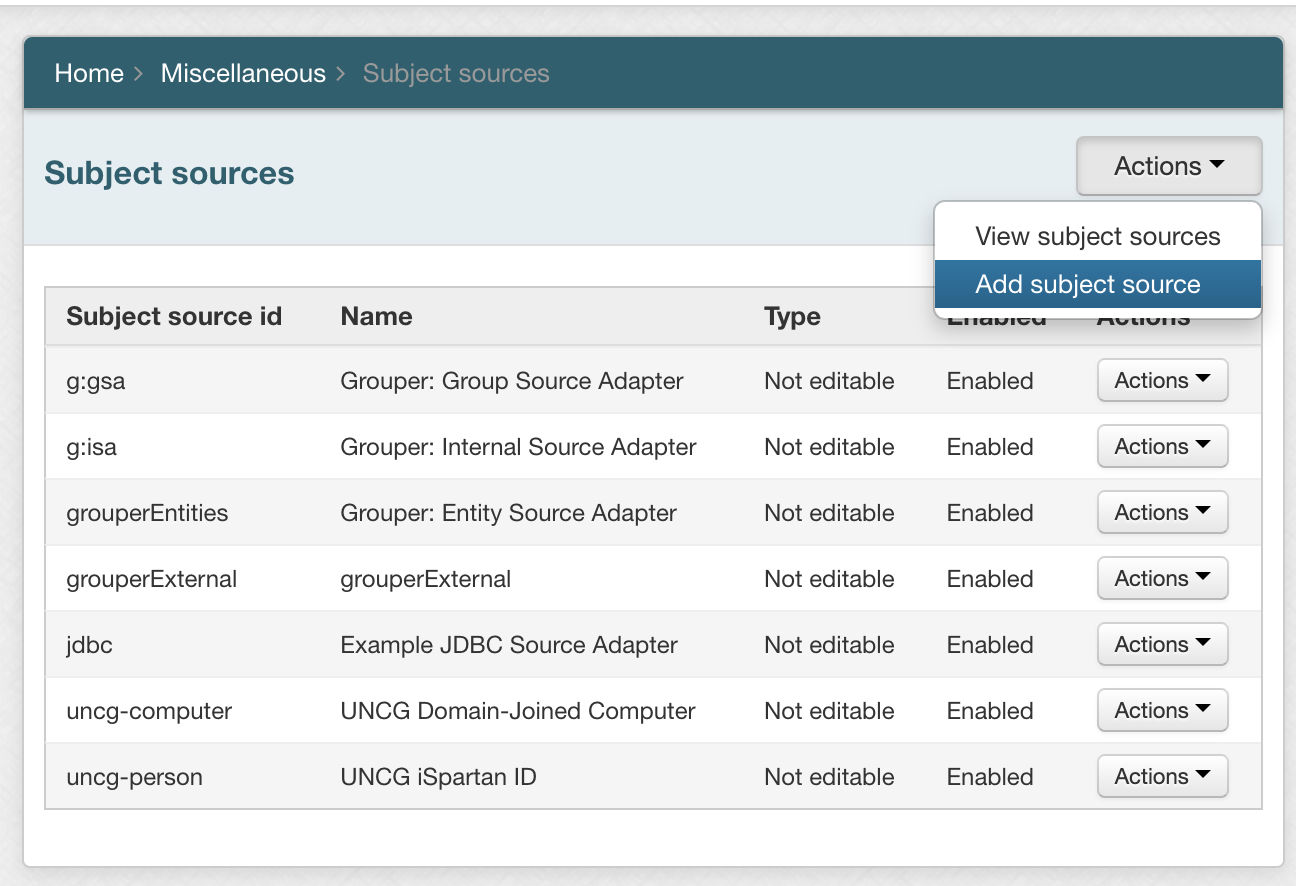
Before running Grouper you need to configure a subject source. This is done in Home → Miscellaneous → Subject sources.
To add a subject source:
Go to Actions → Add subject source
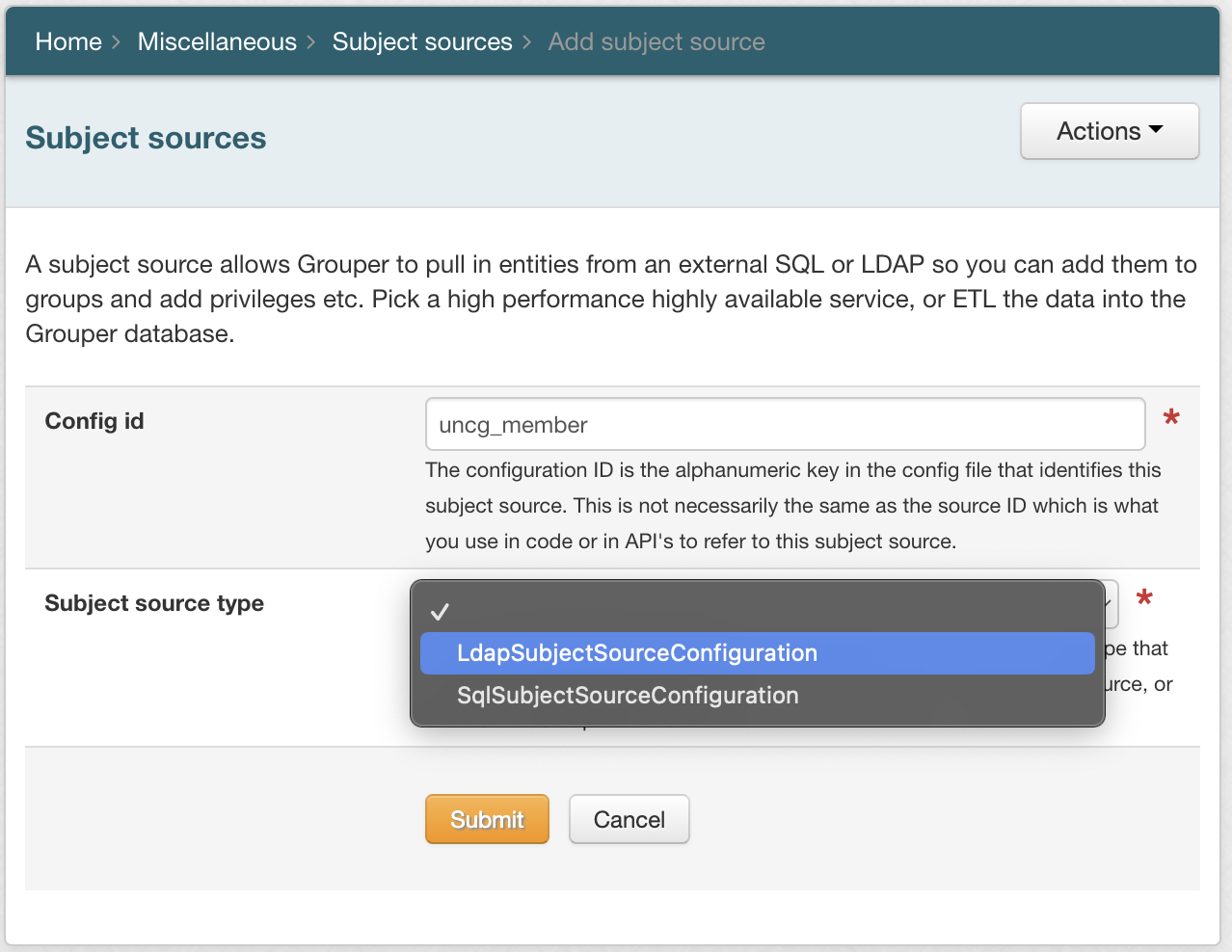
Add:
Config ID - the alphanumeric key in the config file that identifies this subject source. This is not necessarily the same as the source ID which is what you use in code or in API's to refer to this subject source
Subject source type (LDAPSubjectSourceConfiguration or SqlSubjectSourceConfiguration) - Currently Grouper supports these source types. If there is not a source type that you need you need to ETL the data into a database, or build a subject source, or contact the Grouper dev team
Click Submit. The page will update with new sections based on your Subject source type.
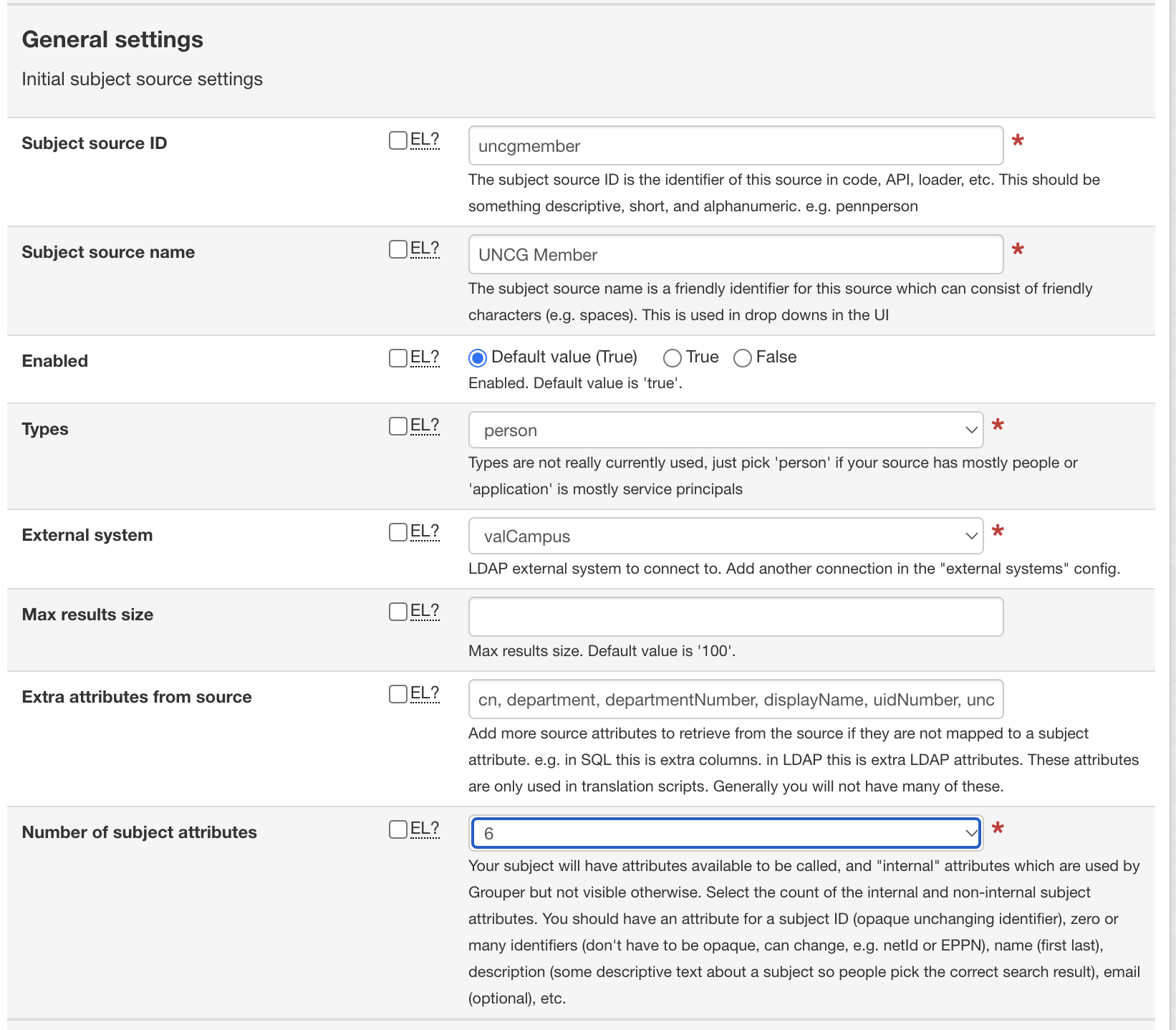
Configure General settings by adding:
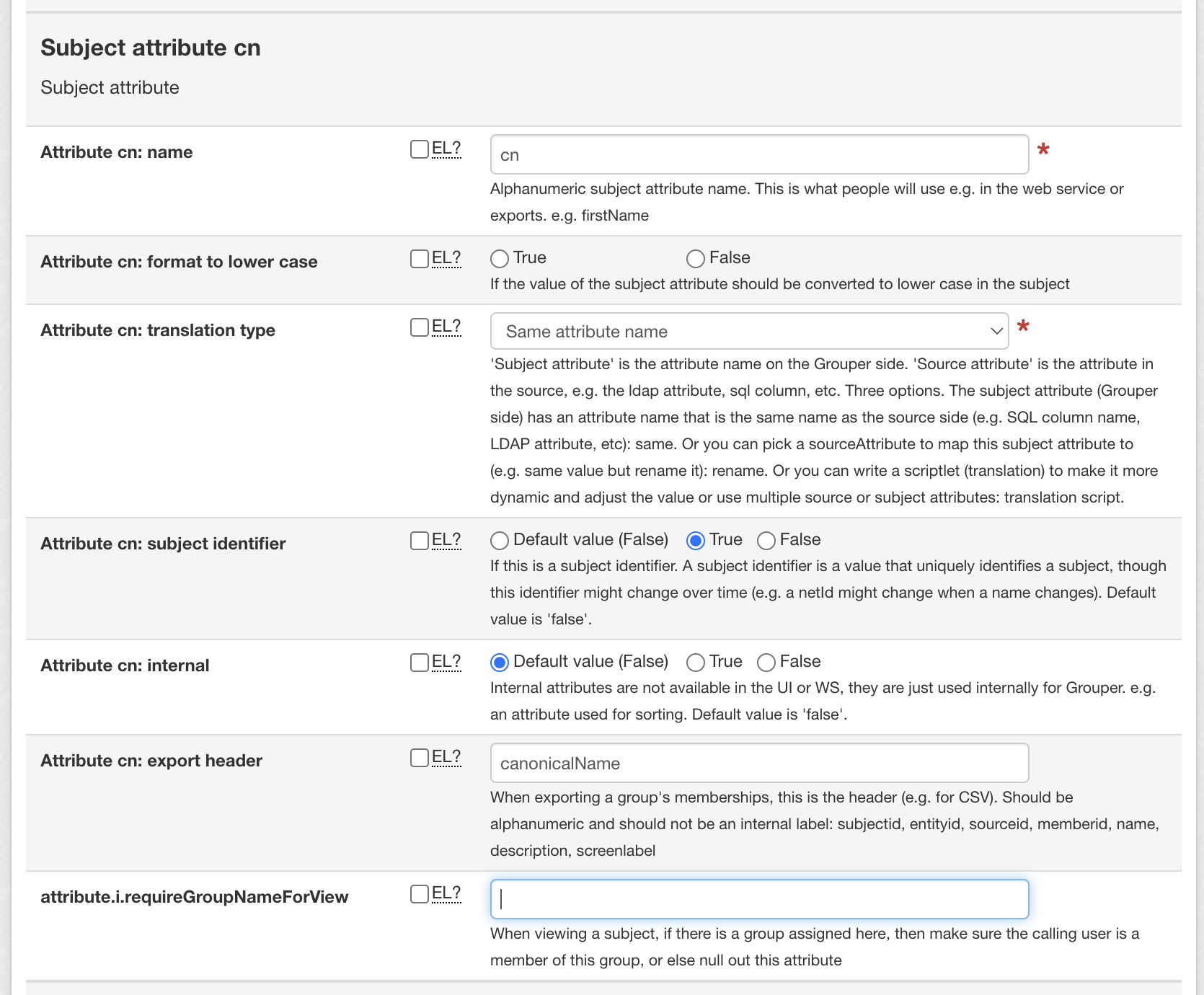
For each subject attribute, configure:
For translation scripts, We may need variables from source, and variables for other subject attributes. suggestion is ${source_attribute__first_name} - gets an attribute from the source query or filter. in this case 'first_name' column ${subject_attribute__description} - references a built in subject field, in this case the description field ${subject_attribute__emailaddress} - references a previously configured subject attribute. in this case "emailAddress". The key is lower case.
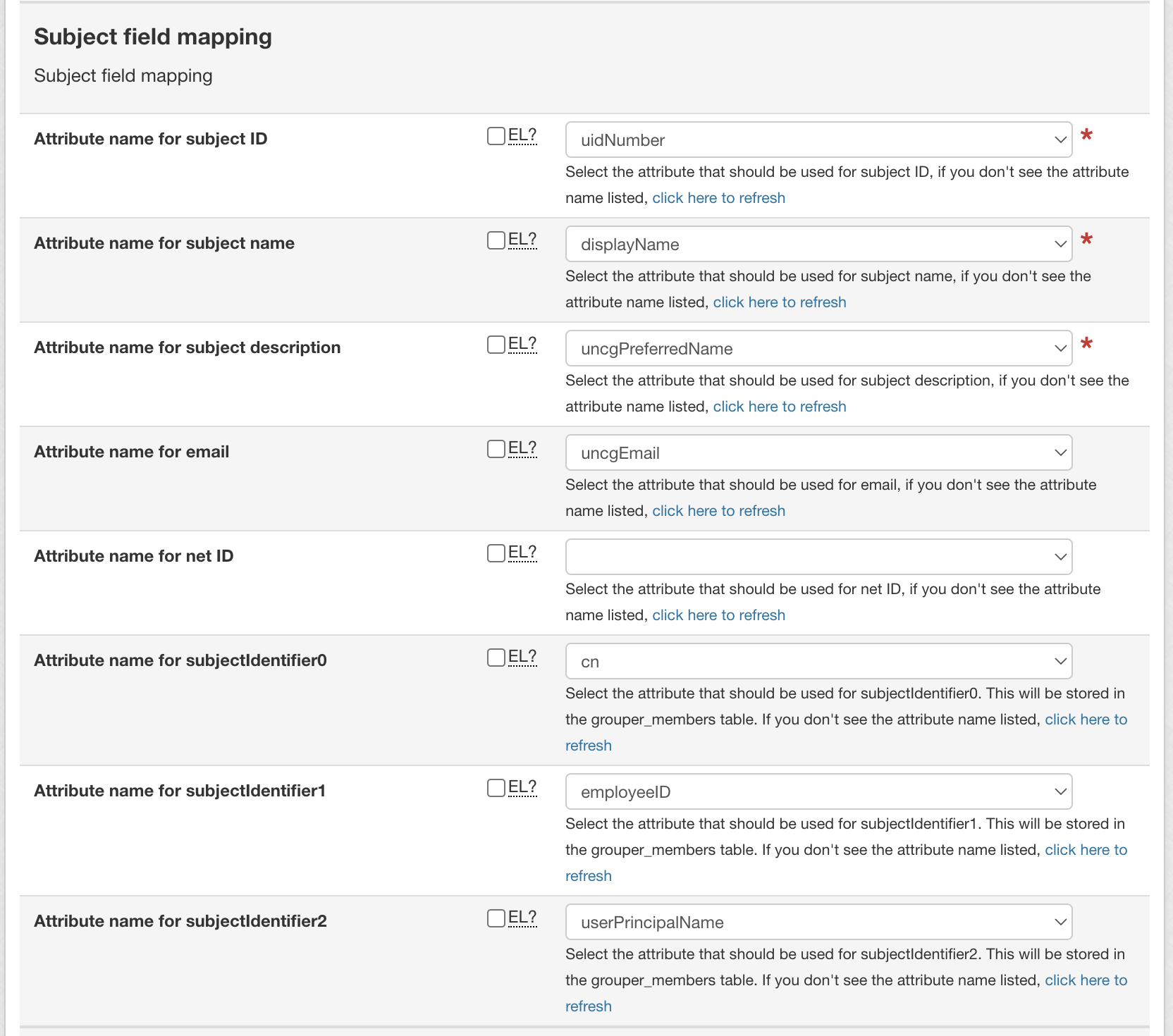
Map subject fields by selecting the desired attributes for:
Subject ID
Name
Description
Email
Net ID
subjectIdentifier0-2
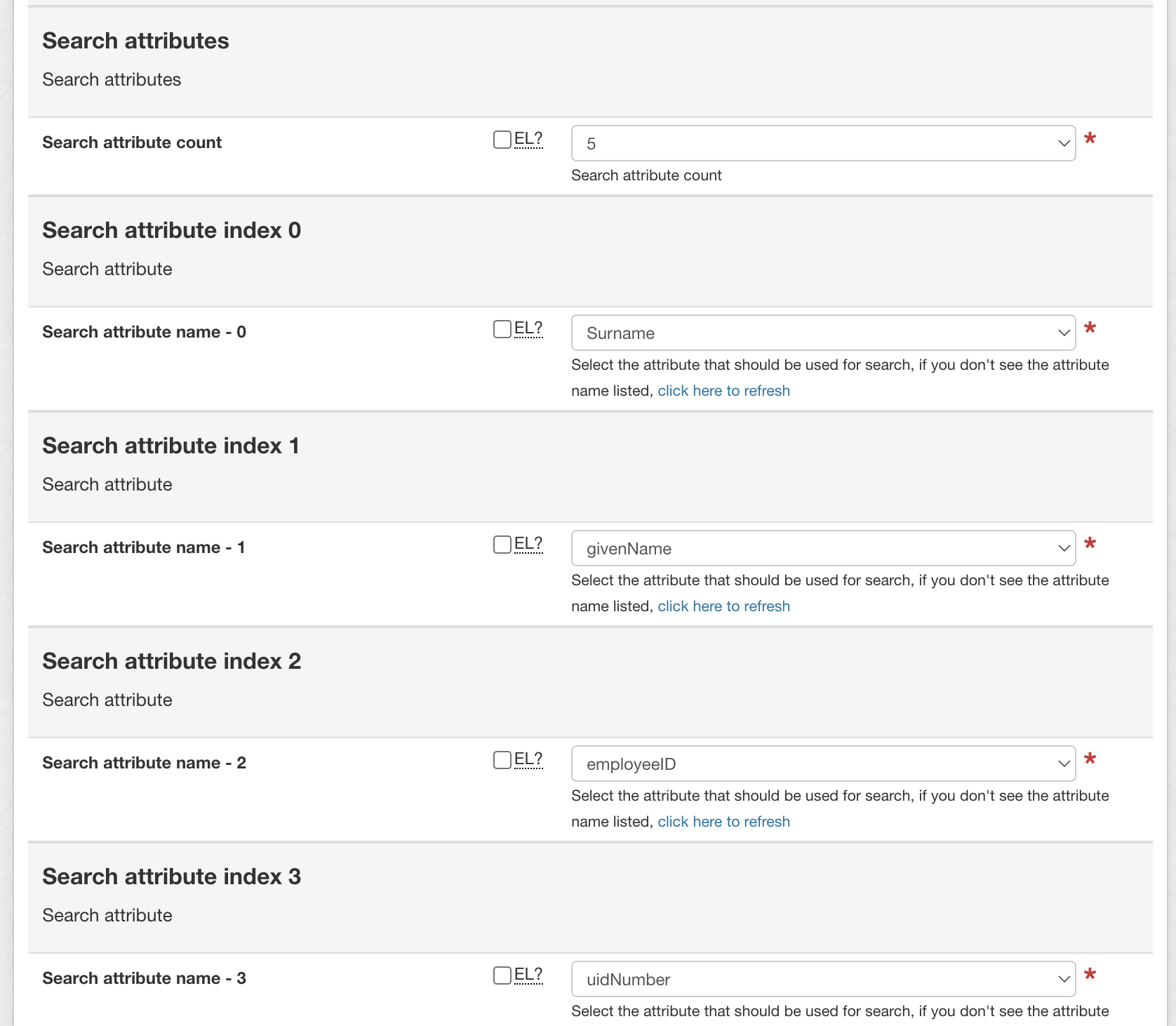
Specify the number of attributes subjects can be searched by [1-5], then select the fields in the resulting drop-downs
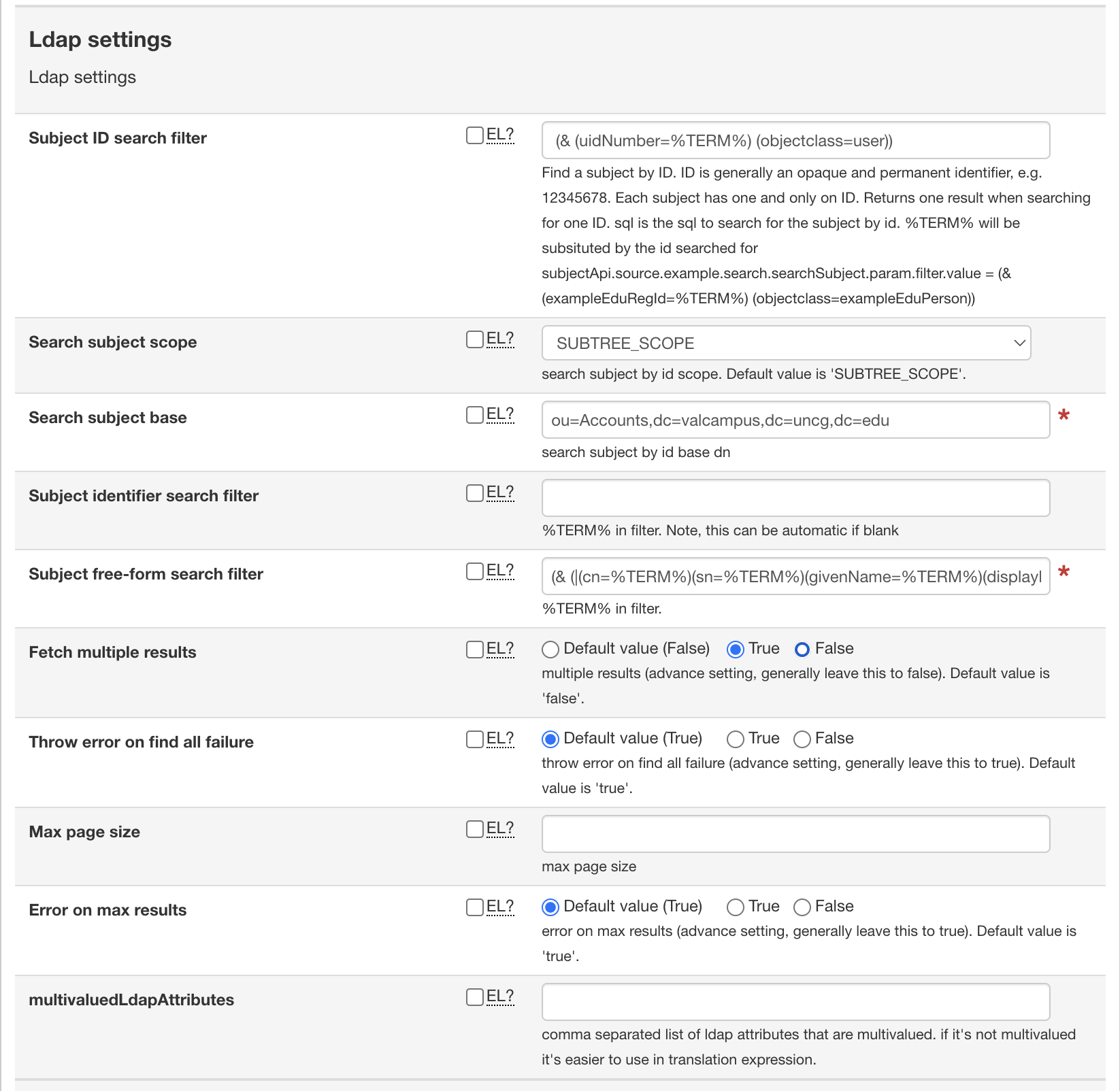
Configure your LDAP Settings
Configure the Configuration Check and Subject Source Diagnostics. Optional, but useful in troubleshooting and initial configuration (TODO: Steps and Screenshots)